Comentários soltos: IA e a cultura das línguas

Para os interessados, o artigo que causou burburinho por causa de um press release do site phis.org, é: Thompson, B., Roberts, S.G. & Lupyan, G. Cultural influences on word meanings revealed through large-scale semantic alignment. Nat Hum Behav (2020). 10.1038/s41562-020-0924-8. Os resultados do artigo são algo um pouco batido: realmente você consegue ter razões extralinguísticas interferindo na distribuição semântica de certas palavras, com graus diferentes de resistência dependendo do tipo sintático de palavra. É algo que os linguistas e antropólogos tem como dado e que o uso de algoritmos de Machine Learning e modelos estatísticos serviria num ambiente academicamente saudável como replicação: uma metodologia X conclui α e uma metodologia independente Y no futuro confirma a conclusão.
Agora, por que as rants de twitter? Bom, o primeiro ponto me parece que o press release foi infeliz, como tem sido recorrente na área de IA: algum pósdoc monta um algoritmo para demonstrar uma aplicação da tecnologia, chega a resultados que a comunidade científica da área acha óbvio e a publicação nos jornais segue o tropo do descobridor assessorado pela mais refinada tecnologia (Newton formulando a teoria das cores dele por ter por acaso o gênio e o prisma). O segundo ponto, que vem disso, é o desconhecimento do press release a respeito da pesquisa já feita na área (inclusive das metaáreas X-computaciona, ex. linguística computacional), desconhecimento esse que é transferido ao pósdoc que tocou a pesquisa. Eu vou tentar sair um pouco aqui do press-release que é absurdamente infeliz até com relação ao artigo original e contar os problemas que eu tenho com o artigo (que é mais interessante no fim do dia).
Nota: muitos comentários assumem que os autores desconhecem linguística e são um bando de cientistas da computação sem noção, mas o artigo demonstra que eles sabem o suficiente e os resultados são interessantes. Os problemas que quero apontar são problemas metodológicos que acabam criando conclusões problemáticas e eu só quero apontar pra ter algo pra fazer no domingo.
Problemas com os dados⌗
A primeira questão que eu tenho é com a qualidade dos dados.
Ao tratar a lista das línguas como dados suplementares e partir para uma generalização linguística “as línguas fazem XYZ” os autores se esquivam de um problema muito sério dos dados deles: super-representação de uma única família linguística.
Não há em lugar nenhum do artigo-base a lista das línguas trabalhadas, ao contrário, estão soltas numa tabelinha do Supplementary Information do artigo.
Eu reproduzo aqui a tabela (aliás, tem tão poucas famílias linguísticas que foi o regex mais fácil da minha vida).
| Language | ISO2 | Language Family |
|---|---|---|
| Arabic | ar | Afro-Asiatic |
| Armenian | hy | Indo-European |
| Azerbaijani | az | Turkic |
| Basque | eu | Basque |
| Belarusian | be | Indo-European |
| Bulgarian | bg | Indo-European |
| Catalan | ca | Indo-European |
| Chinese | zh | Sino-Tibetan |
| Croatian | hr | Indo-European |
| Czech | cs | Indo-European |
| Danish | da | Indo-European |
| Dutch | nl | Indo-European |
| English | en | Indo-European |
| Estonian | et | Uralic |
| Finnish | fi | Uralic |
| French | fr | Indo-European |
| Georgian | ka | Kartvelian |
| German | de | Indo-European |
| Greek | el | Indo-European |
| Hebrew | he | Afro-Asiatic |
| Hindi | hi | Indo-European |
| Hungarian | hu | Uralic |
| Italian | it | Indo-European |
| Japanese | ja | Japonic |
| Kazakh | kk | Turkic |
| Korean | ko | Koreanic |
| Lithuanian | lt | Indo-European |
| Norwegian (Bokmål) | no | Indo-European |
| Persian | fa | Indo-European |
| Polish | pl | Indo-European |
| Portuguese | pt | Indo-European |
| Romanian | ro | Indo-European |
| Russian | ru | Indo-European |
| Slovak | sk | Indo-European |
| Slovenian | sl | Indo-European |
| Spanish | es | Indo-European |
| Swedish | sv | Indo-European |
| Tamil | ta | Dravidian |
| Turkish | tr | Turkic |
| Ukrainian | uk | Indo-European |
| Uzbek | uz | Turkic |
Eu transformei isso por curiosidade num .csv e fui brincar com os dados.
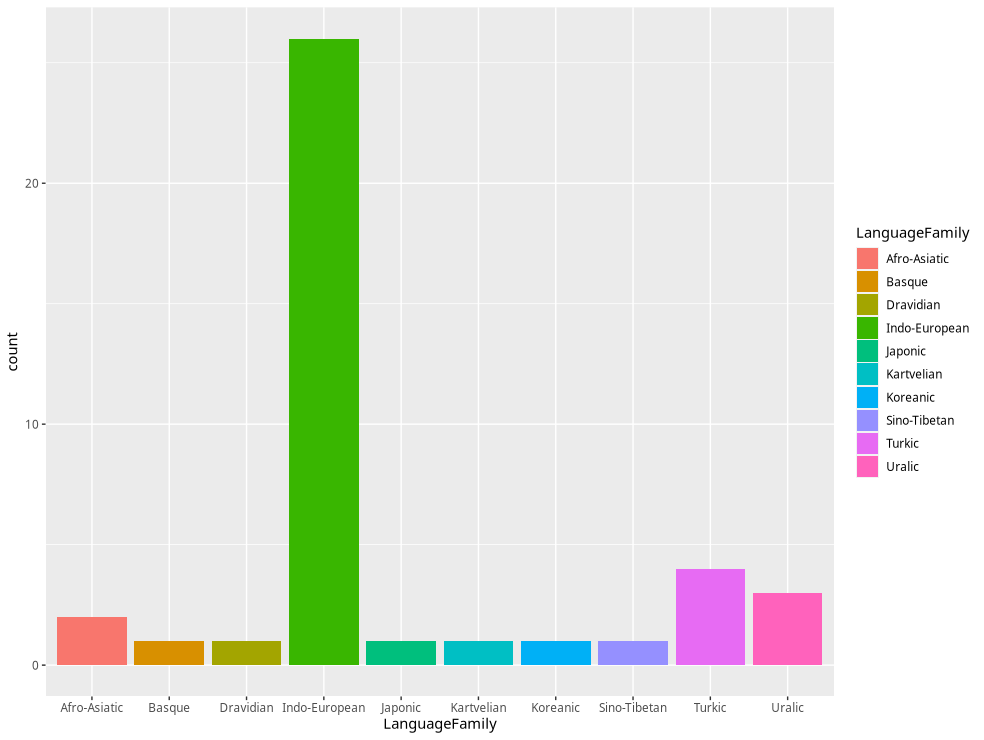
Fazendo uma breve conta, é possível ver que as línguas Indo-Europeias representam algo como 63.4% das 41 línguas que foram analisadas no artigo.
LanguageFamily n
<chr> <int>
1 Afro-Asiatic 2
2 Basque 1
3 Dravidian 1
4 Indo-European 26
5 Japonic 1
6 Kartvelian 1
7 Koreanic 1
8 Sino-Tibetan 1
9 Turkic 4
10 Uralic 3
Talvez uma imagem deixe mais dramático:
O modelo deles lida com a distância história apenas entre as línguas indo-europeias, mas um bom jeito de resolver essa situação era:
- restringir as conclusões às línguas IE; ou
- aplicar o modelo nas IE, depois nas não IE e comparar os resultados.
No caso da segunda opção, eu ainda acharia problemático a falta de informação sobre dialetos e variantes e a falta de línguas minoritárias e de populações de periferias da globalização. Não pelo efeito token, mas para minimizar os efeitos possíveis da variável contato geo e demográfico. Sem isso, as conclusões são restritas às “línguas com acesso mínimo à wikipedia, incluindo azerbaijano e georgiano”, sob pena de você ter um enviesamento muito sério.
Termos de parentesco, dias da semana, etc⌗
Muita gente percebeu que a similaridade das palavras para dia das semanas e termos de parentesco era um problema. Os antropólogos sabem que termos de parentesco são bastante variáveis entre as culturas, mas o artigo coloca eles, numerais e dias da semana como aqueles que são mais correlacionados entre as línguas, enquanto outros grupos semânticos são sensivelmente mais dissimilares. Eu retorno aqui ao ponto anterior: os dados representam línguas de uma certa família linguística muito mais do que outras e mesmo as línguas de troncos diferentes podem ser agrupadas dentro de um mesmo grupo cultural, especialmente dada a falta de informação dialetal.
Os autores assumem que os sistemas de parentesco variam, mas que os termos de relações familiares próximas são organizados de maneira relativamente simples e que isso produziu o alinhamento:
Although kinship systems vary, terms denoting close kin relations are organized along a few dimensions such as gender (son/daughter, mother/father) and generation (grandmother/mother/daughter). This low dimensionality seems to enable high alignment.
O problema ao meu ver é que os termos mais alinhados são filho, filha e tia. Embora pai/mãe e avô/avó não estarem nessa lista levante alguns problemas bem sérios, talvez tia seja o mais surpreendente, dado que irmão-de-pai/mãe e irmã-de-pai/mãe são exatamente onde os sistemas de parentesco passam a divergir mais intensamente. A explicação aqui é capenga: ela cobre os termos que não apresentam alinhamento no modelo enquanto não discute os termos que não tem o alinhamento previsto (tia) mas que mostram alto alinhamento. Sem uma explicação para a correlação apresentada, fica parecendo que os autores não tem uma e derivam dos dados uma conclusão que os dados agregados não necessariamente sustentam. O mesmo se dá com os dias da semana: não há um grupo de controle pra uma variável que cubra diferentes sistemas de divisão temporal, de modo que ao mesmo tempo a correlação pode ser causada por uma tendência linguística-cultural ou por um enviesamento dos dados.
Escopo e dados⌗
No fim, o artigo parece pecar ao dar conclusões em um escopo imenso (as línguas e suas culturas) usando dados que cobrem um bloco linguístico e cultural muito restrito e conectado demais. O método de análise (vector space models) tem uns resultados bem interessantes em trabalhos mais focados (eu não posso deixar de mencionar o trabalho de pessoas conhecidas como Rodda, Probert e McGillivray Vector space models of Ancient Greek word meaning, and a case study on Homer, pelo qual fui saber do método), mas dado o escopo da generalização, o artigo faz parecer que o método é falho ou desnecessário (um canhão laser para matar uma mosca já morta). O próprio fato do artigo não discutir aplicações prévias do modelo é um tiro no pé.
Enfim, isso é uma rant desenvolvida. Espero que alguém com mais propriedade responda o paper e que tenha a mesma mídia que o tal paper, mas nós sabemos que a segunda parte não vai acontecer. Então espero que todo mundo fique suave e talvez leia o artigo, é divertido e os dados e scripts tão disponíveis para brincar.